 |
|
|
- (02/2025) One paper is accepted by CVPR2025!
- (02/2024) One paper is accepted by CVPR2024!
- (08/2022) I started my PhD at CMU SCS.
- (07/2022) One paper is accepted by ECCV2022!
- (06/2022) I graduated from Peking University!
- (09/2021) One paper is accepted by NeurIPS2021 as Spotlight!
- (07/2021) One paper is accepted by ICCV2021!
- (07/2021) I am selected as "Top 10 Outstanding Researcher" (学术十杰), EECS of Peking University!
- (03/2021) One paper is accepted by CVPR2021!
- (12/2020) One paper is accepted by AAAI2021!
- (07/2020) One paper is accepted by ECCV2020!
- (06/2020) One paper is accepted by ICPR2020.
- (03/2020) One paper is accepted by CVPR2020!
- (09/2019) I began my graudate study in CS at PKU.
Publications (Full list can be found here.)
 |
Turbo3D: Ultra-fast Text-to-3D Generation
|
|
 |
MVD-Fusion: Single-view 3D via Depth-consistent Multi-view Generation
|
|
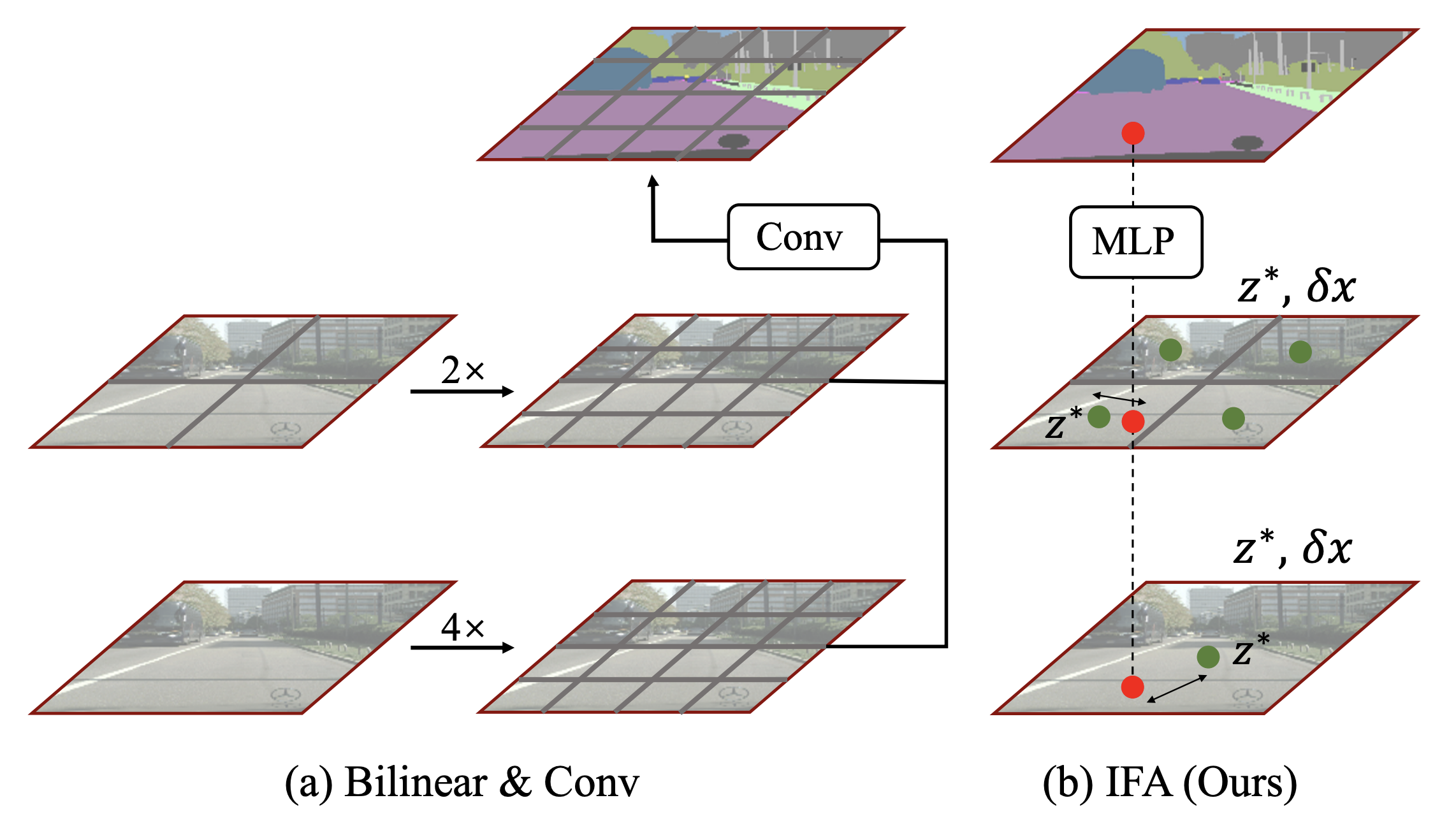 |
Learning Implicit Feature Alignment Function for Semantic Segmentation |
|
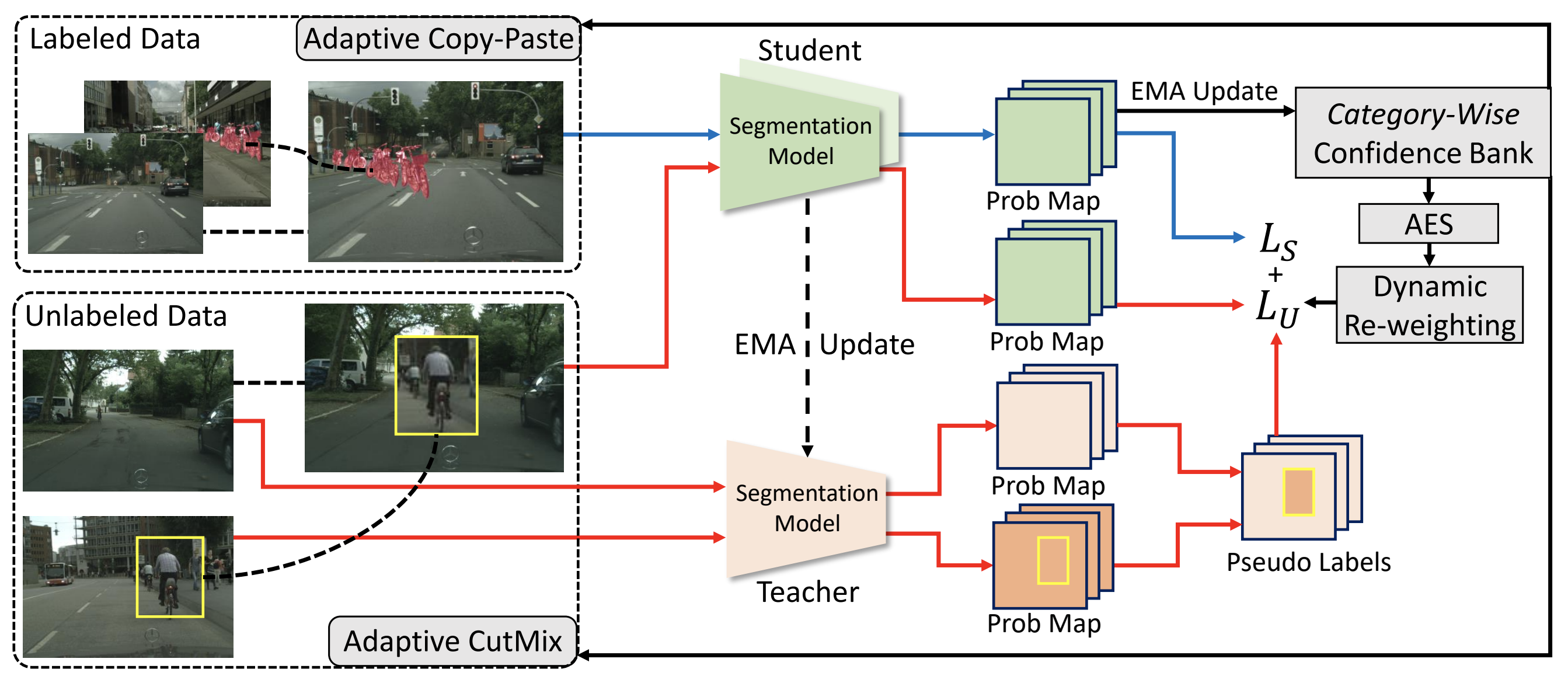 |
Semi-Supervised Semantic Segmentation via Adaptive Equalization Learning |
|
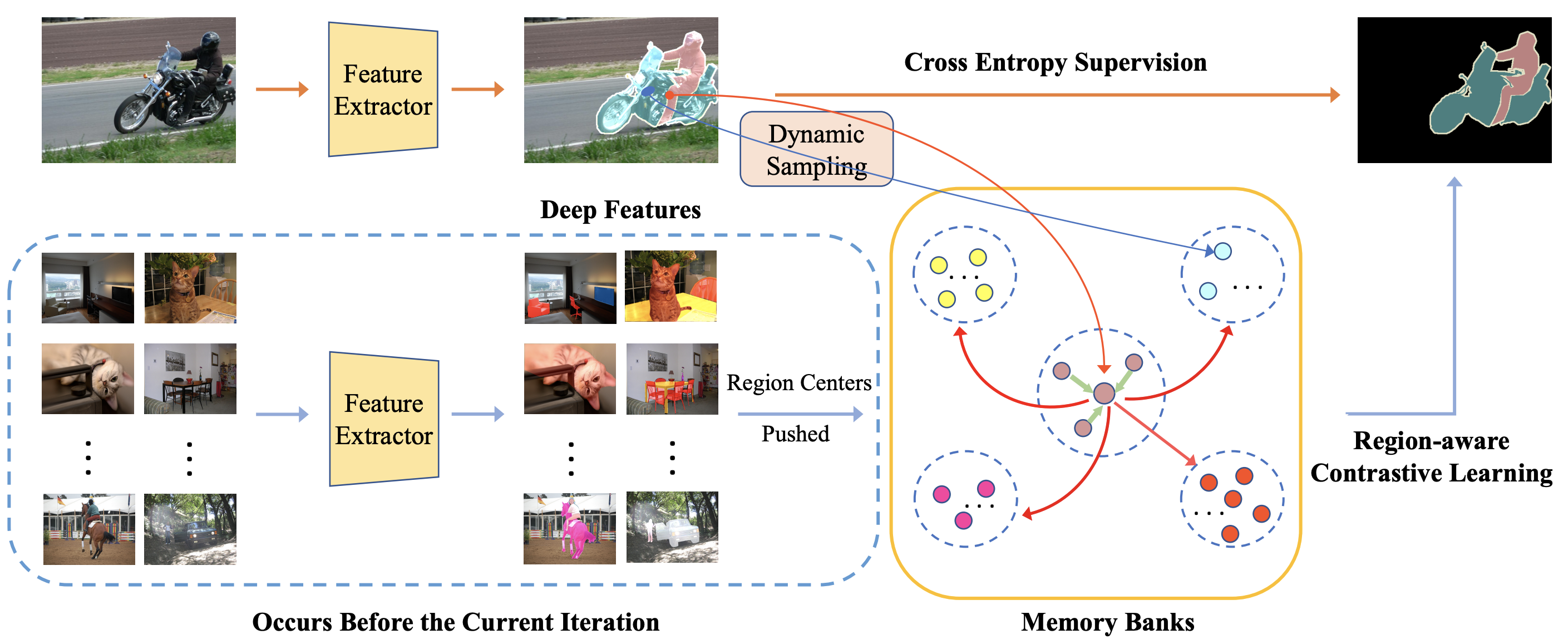 |
Region-aware Contrastive Learning for Semantic Segmentation |
|
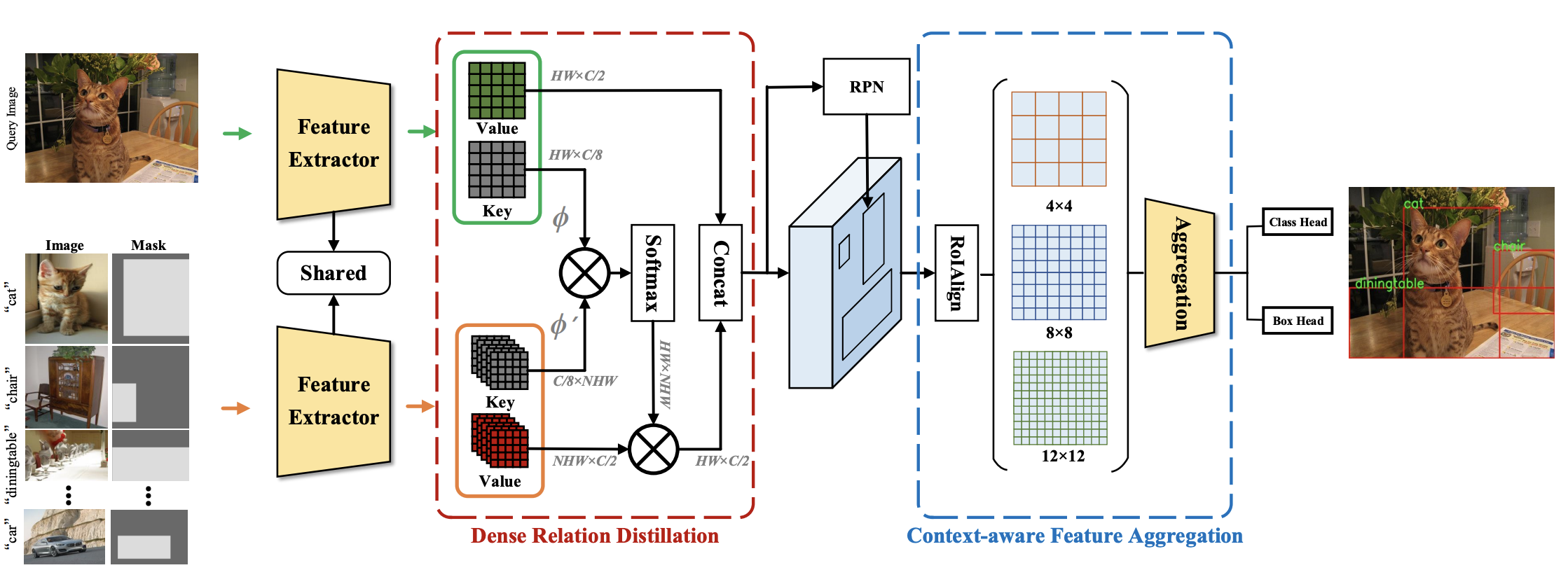 |
Dense Relation Distillation with Context-aware Aggregation for Few-Shot Object Detection |
|
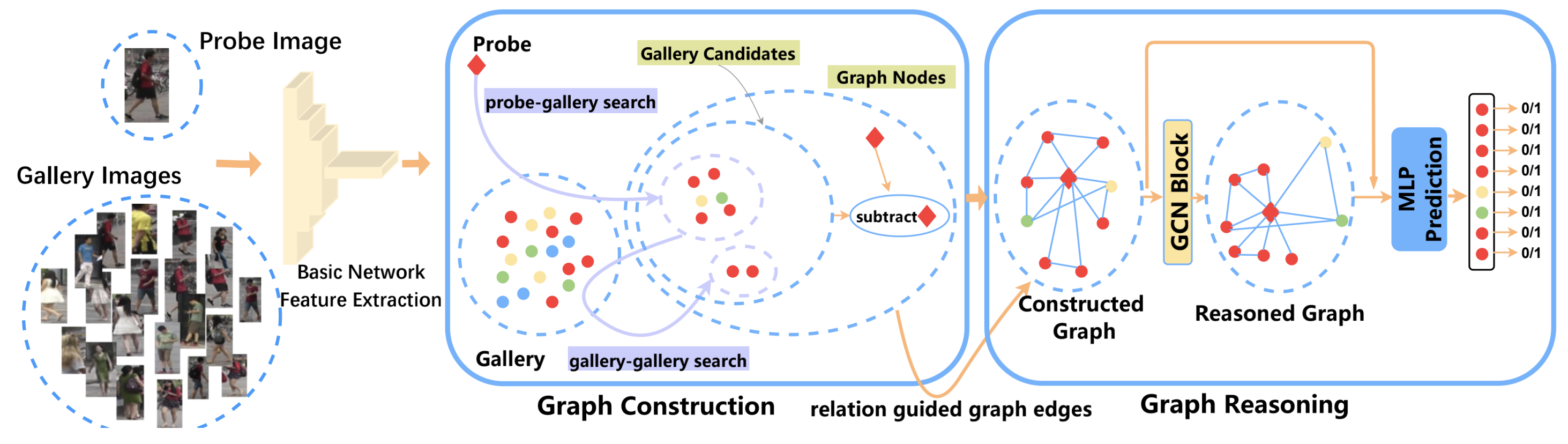 |
Context-aware Graph Convolution Network for Target Re-identification |
|
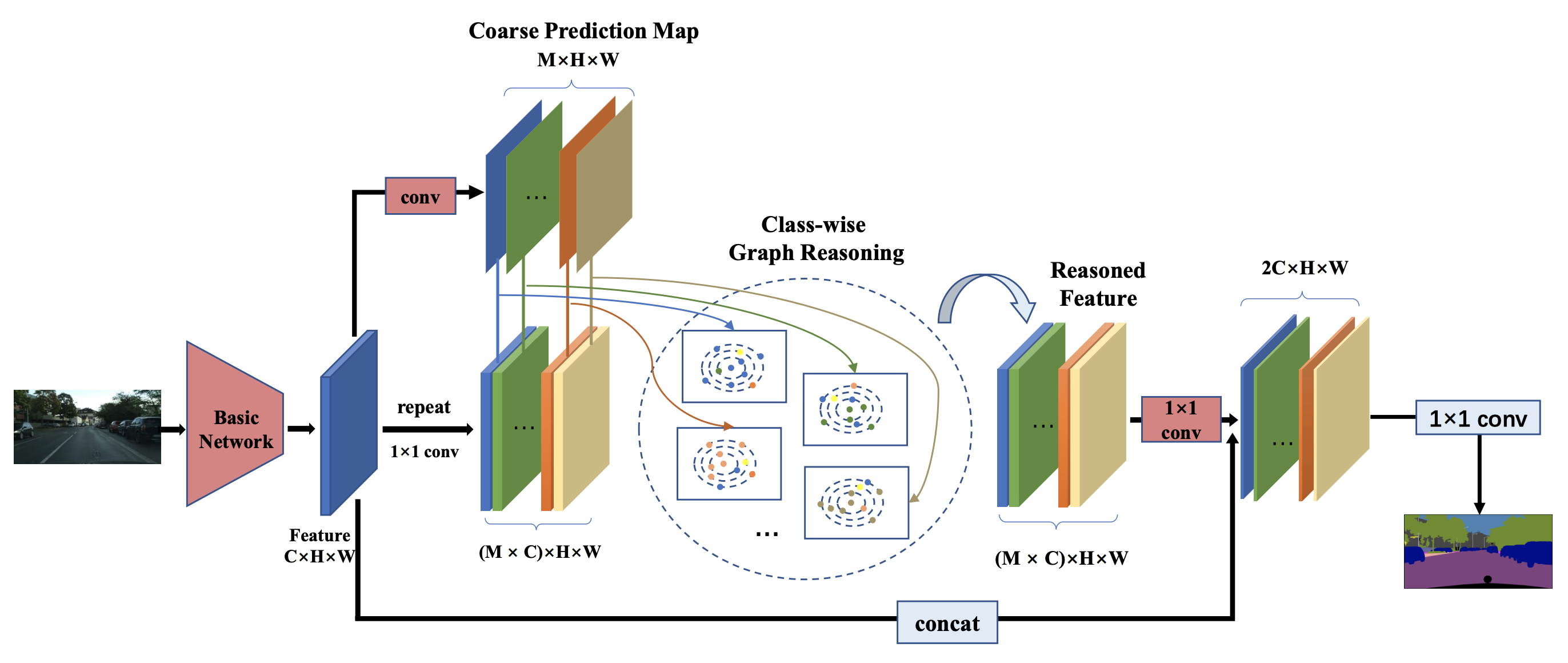 |
Class-wise Dynamic Graph Convolution for Semantic Segmentation |
|
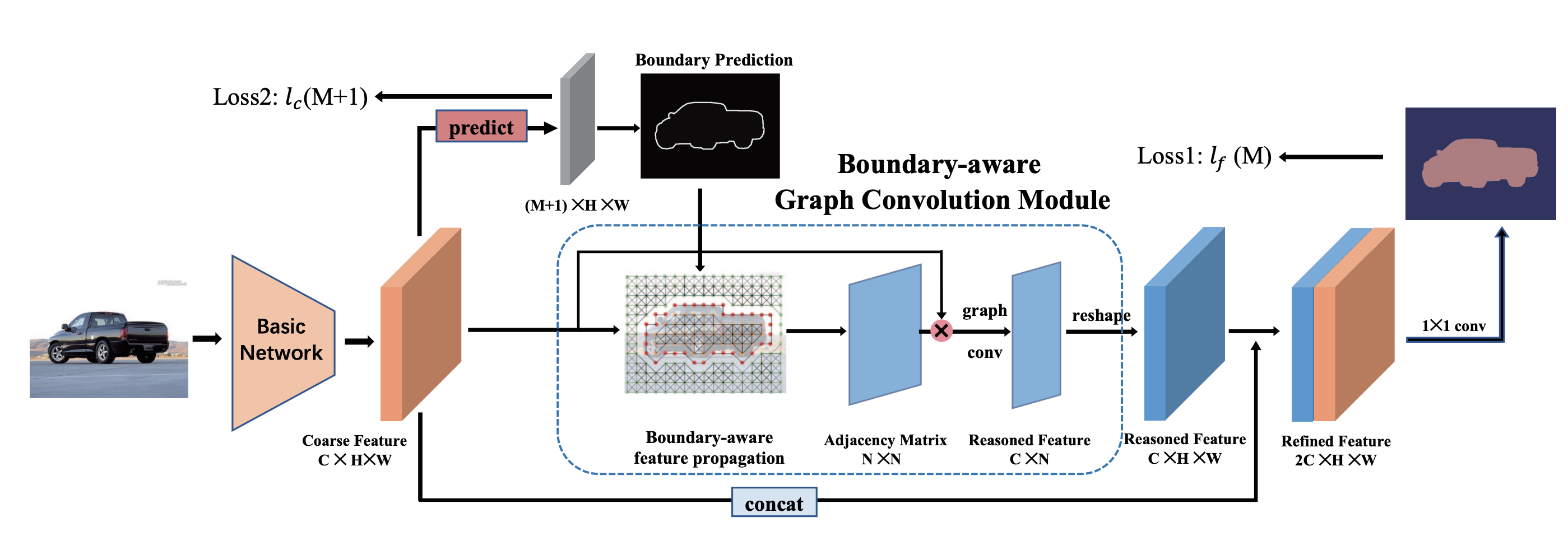 |
Boundary-aware Graph Convolution for Semantic Segmentation |
|
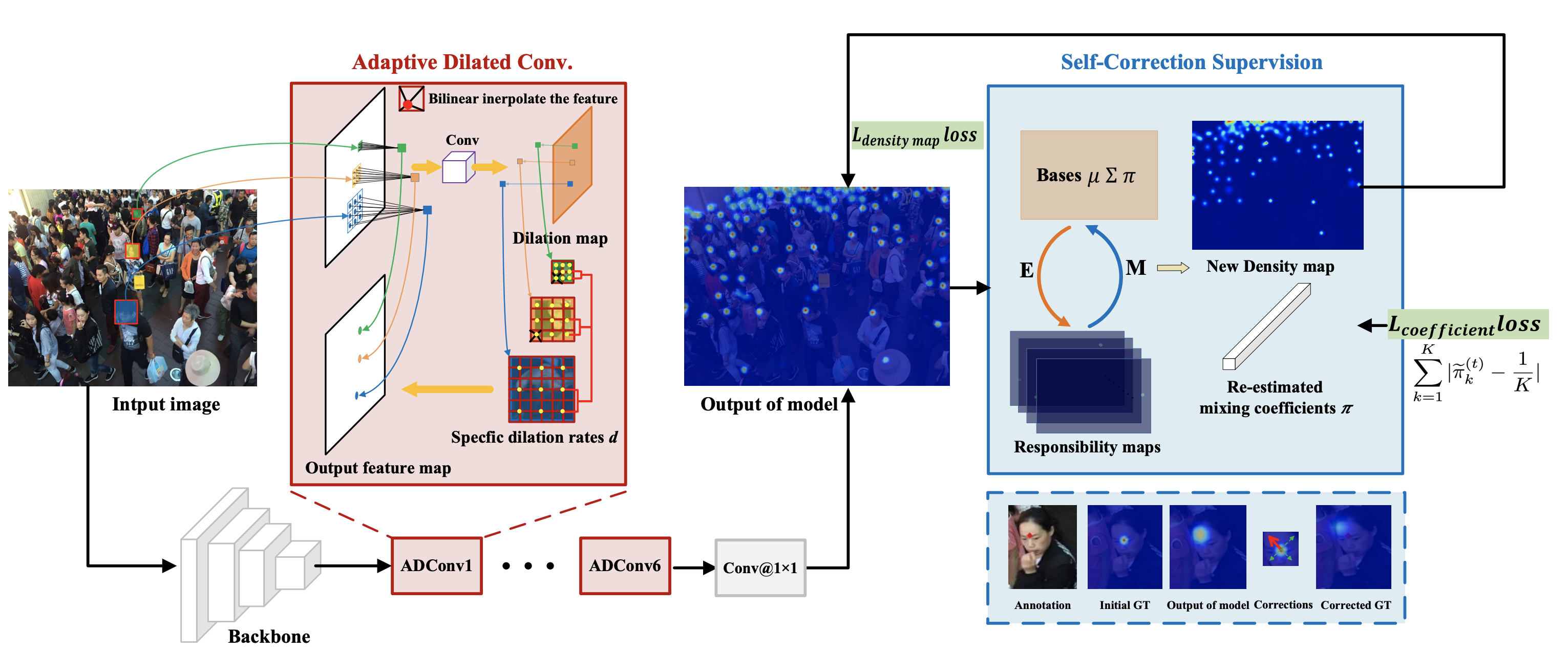 |
Adaptive Dilated Network with Self-Correction Supervision for Counting |
Academic Services
-
Conference Reviewer
- CVPR, ICCV, ECCV, NeurIPS, ICML, ICLR, ACM Siggraph, ACM Siggraph Asia, AISTATS, 3DV, BMVC, WACV
-
Journal Reviewer
- TPAMI, TIP, IJCV, TNNLS, TCSVT, Neurocomputing
-
Seminar Organizer
- CMU Computer Vision Reading Group
| ▪ | May 2024 – Jan 2025 |
Adobe Research, San Jose, CA Research Scientist Intern |
| ▪ | Mar 2021 – Jun 2021 |
Microsoft Research, Beijing, China Research Intern |
- 16-824: Visual Learning and Recognition. TA, Spring 2025
- 16-825: Learning for 3D Vision. TA, Fall 2025
- Award for Academic Innovation, Peking University, 2021
- Merit Student of Peking University, 2021
- Top 10 Outstanding Researcher (学术十杰), EECS, Peking University, 2021
- Scholarship for Outstanding Research, 2020
- Peking University Scholarship, 2019
- Xingquan Scholarship, Nanjing University, 2018
- Scholarship for Outstanding Student, Nanjing University, 2018
|
Label-Efficient Learning for Object Recognition |